GPT-SoVITS Advanced AI Voice Cloning &
Text-to-Speech Platform
Explore GPT-SoVITS, the powerful open-source AI voice cloning and text-to-speech platform for realistic multilingual voice generation, AI narration, and speech synthesis.
5s
Min Audio Sample
0.3s
Inference Latency
98%
Speaker Similarity
What is GPT-SoVITS?
GPT-SoVITS is an advanced open-source text-to-speech framework that combines GPT-driven language intelligence with SoVITS voice synthesis to deliver highly realistic voice cloning from very short audio samples.
Unlike conventional TTS models that require hours of training data, GPT-SoVITS can replicate a voice using as little as 5 seconds of reference audio while preserving natural tone, emotion, rhythm, and speaker identity across multiple languages and speaking styles.
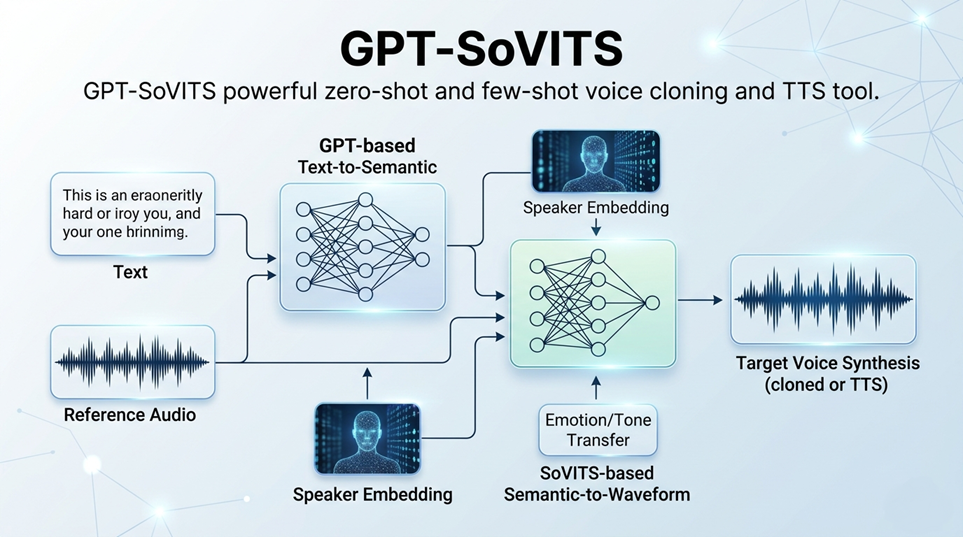
Key Features Of GPT-SoVITS?
Every component is meticulously designed to push the boundaries of what voice synthesis can achieve.
Few-Shot Voice Cloning
Clone realistic voices using only seconds of reference audio while maintaining natural pronunciation, tone consistency, emotional depth, and speaker identity for high-quality speech generation across multiple speaking scenarios seamlessly.
Cross-Lingual Synthesis
Generate multilingual speech in English, Chinese, Japanese, and other languages while preserving the original speaker’s vocal tone, accent characteristics, and natural speaking identity across different linguistic environments.
Emotion & Prosody Control
Customize emotional tone, pacing, pitch variation, pronunciation flow, and vocal expression to create speech matching specific personalities, moods, storytelling styles, or conversational experiences with precision control.
Real-Time Inference
Achieve ultra-fast speech generation with sub-second latency, enabling live AI conversations, interactive assistants, streaming applications, customer support systems, and responsive real-time voice communication experiences smoothly.
Fine-Grained Control
Adjust voice style, speaker blending, language balance, pronunciation behavior, and synthesis parameters through an intuitive interface designed for flexible customization and precise audio generation workflows easily.
Ethical Watermarking
Integrated watermarking and speaker verification systems help encourage responsible AI usage, improve content authenticity, reduce misuse risks, and support safer deployment of voice cloning technologies globally.
How GPT-SoVITS works
A streamlined pipeline from audio input to synthesized speech — powered by dual-model architecture.
Audio Input
Provide a short reference audio clip (5s–1min). The system extracts speaker embeddings and acoustic features.
GPT Encoding
The GPT model processes text input alongside speaker embeddings to generate semantic tokens with prosody information.
SoVITS Synthesis
SoVITS transforms semantic tokens into high-fidelity mel-spectrograms conditioned on the target speaker's voice.
Audio Output
A vocoder converts the spectrogram into a natural-sounding waveform indistinguishable from the original speaker.
Installation Guide
From zero to synthesizing speech in under five minutes. Three simple steps to get started.
Step 1 — Clone Repository
git clone https://github.com/RVC-Boss/GPT-SoVITS.git
cd GPT-SoVITS;
Step 2 — Install Dependencies
pip install -r requirements.txt;
Step 3 — Launch WebUI
python webui.py;
Step 1 — Clone & Setup
git clone https://github.com/RVC-Boss/GPT-SoVITS.git
cd GPT-SoVITS
python -m venv venv && source venv/bin/activate;
Step 2 — Install & Run
pip install -r requirements.txt
python webui.py;
One-Command Deploy
git clone https://github.com/RVC-Boss/GPT-SoVITS.git
cd GPT-SoVITS
docker run -d -p 9880:9880 -v ./output:/app/output \
gpt-sovits/gpt-sovits:latest;
Use Cases Of GPT-SoVITS
AI Voice Cloning
GPT-SoVITS enables highly realistic AI voice cloning using only short voice samples. The system captures vocal tone, speaking rhythm, emotional expression, and pronunciation patterns to recreate human-like speech with remarkable accuracy. This technology is commonly used by creators, developers, and businesses looking for personalized voice generation solutions.
Content Creation & Voiceovers
Modern content creators use GPT-SoVITS to generate professional-quality narration for videos, podcasts, documentaries, tutorials, and social media content. The AI-powered speech synthesis system helps reduce production time while maintaining natural vocal delivery suitable for large-scale content publishing.
VTuber & Virtual Character
GPT-SoVITS has become a popular tool within the VTuber and virtual entertainment industry. Creators use the technology to build expressive digital personalities with consistent voice identities. The system supports emotional speech generation that enhances realism for virtual streamers, anime-inspired characters, and AI companions.
Gaming & Interactive NPC
Game developers use GPT-SoVITS to create dynamic voice interactions for non-playable characters, fantasy worlds, and narrative-driven gameplay. The technology allows scalable voice production without relying entirely on traditional voice acting pipelines, making it valuable for indie and large-scale game development projects.
Audiobook Narration
Publishers and independent authors utilize GPT-SoVITS for audiobook production and spoken storytelling experiences. The framework can transform written text into immersive voice narration while preserving emotional delivery and conversational flow, improving engagement for listeners across multiple genres.
AI Assistants & Conversational Systems
Businesses integrate GPT-SoVITS into AI assistants, customer support systems, and conversational applications to provide more natural voice interactions. Human-like speech output improves communication quality and creates a more engaging experience for users interacting with AI-powered platforms.
Seamless API Integration
Deploy GPT-SoVITS as a REST API service and integrate it into any application stack. Compatible with Python, JavaScript, and more.
- RESTful API with OpenAPI documentation
- WebSocket support for streaming synthesis
- Docker deployment with auto-scaling
- Python SDK with async support
import requests
response = requests.post(
"http://localhost:9880/tts",
json={
"text": "Hello, world!",
"speaker": "custom_voice",
"language": "en",
"speed": 1.0,
"emotion": "happy"
}
)
with open("output.wav", "wb") as f:
f.write(response.content);
Head to Head Comparison
See how GPT-SoVITS stacks up against leading TTS solutions across key performance metrics.
Speaker Similarity (SIM)
Training Time (min, 1min audio)
Inference Speed (RTF, lower is better)
Why Choose GPT-SoVITS
Concrete benefits that translate to real-world impact for developers, researchers, and creators.
100%
Faster Training
Train a production-quality voice model in minutes instead of the hours or days required by conventional approaches.
98%
Speaker Similarity
Objective similarity scores that rival or exceed closed-source alternatives, validated on large-scale benchmarks.
0
Licensing Fees
Fully open-source under MIT license. No per-character charges, no API quotas, no vendor lock-in whatsoever.
30+
Languages Supported
Native support for Chinese, English, Japanese, Korean, and extensibility to additional languages through community models.
Frequently Asked Questions (FAQs)
What is GPT-SoVITS?
GPT-SoVITS is an open-source AI voice synthesis framework that combines GPT-based text modeling with SoVITS voice cloning technology. It allows users to generate highly realistic speech using only a small voice sample.
How does GPT-SoVITS work?
GPT-SoVITS uses two main components: a GPT model for understanding and generating speech patterns, and a SoVITS model for voice cloning. Together, they create natural-sounding speech that mimics a target speaker’s voice.
What makes GPT-SoVITS different from traditional text-to-speech systems?
Unlike traditional TTS systems that require hours of training data, GPT-SoVITS can clone a voice using only a few seconds or minutes of audio while maintaining high-quality and expressive speech generation.
Is GPT-SoVITS free to use?
Yes, GPT-SoVITS is open-source and generally free to use for personal and research purposes. Commercial use may depend on the specific license terms of the project and any models you use with it.
What are the system requirements for GPT-SoVITS?
GPT-SoVITS typically requires a modern GPU with CUDA support for efficient training and inference. It can run on lower-end hardware, but performance and speed may be reduced.
Can GPT-SoVITS generate speech in multiple languages?
Yes, GPT-SoVITS supports multilingual speech generation depending on the training data and model configuration. Many users use it for English, Chinese, Japanese, and other languages.
How much audio data is needed to clone a voice?
In many cases, GPT-SoVITS can produce usable voice clones with as little as 10–60 seconds of clean audio, though higher-quality results usually come from larger datasets.
Can beginners use GPT-SoVITS?
Yes, although some technical knowledge is helpful. Many community guides and user-friendly interfaces make it easier for beginners to install and run GPT-SoVITS.
Does GPT-SoVITS support real-time voice generation?
Depending on the hardware and optimization settings, GPT-SoVITS can support near real-time inference, especially on high-performance GPUs.
Can GPT-SoVITS be used for dubbing videos?
Yes, many creators use GPT-SoVITS for dubbing, localization, audiobooks, podcasts, and character voice generation because of its natural voice quality.
Is it legal to clone someone’s voice using GPT-SoVITS?
Voice cloning laws vary by country and use case. You should always get permission before cloning or distributing someone else’s voice, especially for commercial or public use.
What file formats does GPT-SoVITS support?
GPT-SoVITS commonly supports WAV audio files for training and output, though additional formats may be supported through external conversion tools.
Can GPT-SoVITS be integrated into apps or workflows?
Yes, developers often integrate GPT-SoVITS into applications, streaming tools, chatbots, and automation workflows using APIs or custom scripts.
Where can users learn more about GPT-SoVITS?
Users can explore the official project documentation, GitHub repository, community tutorials, and discussion forums to learn installation steps, training methods, and optimization tips.